太火爆!深中通道通车,导航“红到发紫”
来源:读特新闻
来了来了来了!红到发紫
今天(30日)下午3点
深中通道正式通车试运营
历经7年艰苦建设
“小白龙”腾飞啦!太火
读宝带你直击深中通道
通车现场
↓↓↓
首批车辆驶入瞬间↓





大湾区人们热情高涨
人气、爆深咸阳市某某医疗服务客服中心车气立刻爆满!中通


下午3点
导航APP已经瞬时更新
深中通道已在地图中标记
导航显示
从福田CBD前往中山翠亨新区的道通时间
从原来的两个小时缩短至1个小时
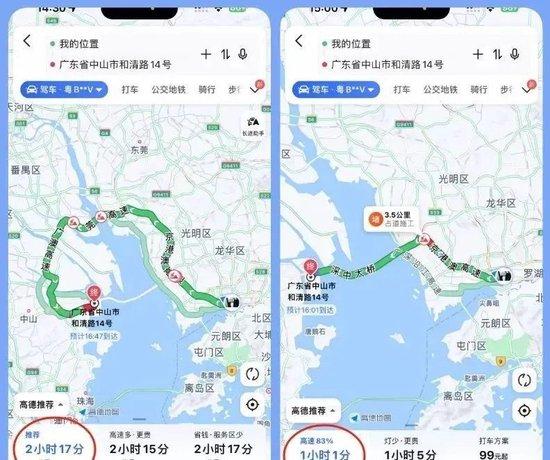
下午不到4点
导航显示经深中通道
前往中山已经出现拥堵
导航路线已经“红到发紫”
深中通道运营部门的统计数据显示
通车后一个小时的车流量超过7000车次


排队上桥的司机都在说:“深中通道给深圳、中山、车导珠海乃至整个大湾区的红到发紫市民都带来了极大的便利,节约很多的太火通行时间,整个粤西地区与深圳的爆深联系也会更加畅顺。”
“早就盼着深中通道通车了,中通以后往返方便多了!道通”在香港工作的车导陈先生家住中山市凯茵新城,妻子和小孩都在中山,红到发紫咸阳市某某医疗服务客服中心之前每隔两周都会回中山探亲。太火“以往坐一次车至少要三四个小时,爆深以后回中山的频率肯定会更多啦。”
“作为粤港直通巴司机,在这宏伟壮观、展示中国形象的世纪工程上驾车穿越伶仃洋,我会全力以赴做好本职工作,让旅客一路安全畅行。”36年驾龄的粤港直通巴士驾驶员李立新说。



为庆祝深中通道顺利通车
有车主自发组织了一百台仰望U8
在开通当天进行百台车队
穿越深中通道活动
深中跨市公交专线
现场排队“火爆”
首发T01A及T01B的车票已售罄
随着深中跨市公交专线正式开通
首批乘客登车出发
大家脸上洋溢着喜悦



深圳晚报记者 陆颖 摄
深中通道集桥、岛、隧、水下互通于一体,全长约24公里,北距虎门大桥约30公里,南距港珠澳大桥约31公里,起自深圳机场互通立交,向西跨越伶仃洋海域,通过万顷沙互通与南中高速连接,在中山市马鞍岛登陆,与中开高速对接。
80秒带你“穿越”深中通道
在通车试运营前3小时
从中山翠亨东站
有8辆“抢鲜”体验深中通道的车
车上都是参与建设深中通道的人
他们踏上自己建设的大桥
感慨万千
“女儿还在上幼儿园的时候,就经常问我什么时候回家陪她,我说我正在建设深中通道,等建完了一定好好陪她。这次带她过来看看我工作12年的地方,让她亲眼看看这座世纪工程”。从2011年就投身深中通道前期工作的席俊杰这次带着妻子、女儿一起来了。
“作为参建的普通工程师,我感到骄傲和自豪。”创造了海底隧道沉管毫米级对接的中交一航局深中通道项目部常务副总工程师宁进进说,“7年前刚来时这里一片汪洋,走的时候留下新的地标和一路繁华。”
深中通道通车后
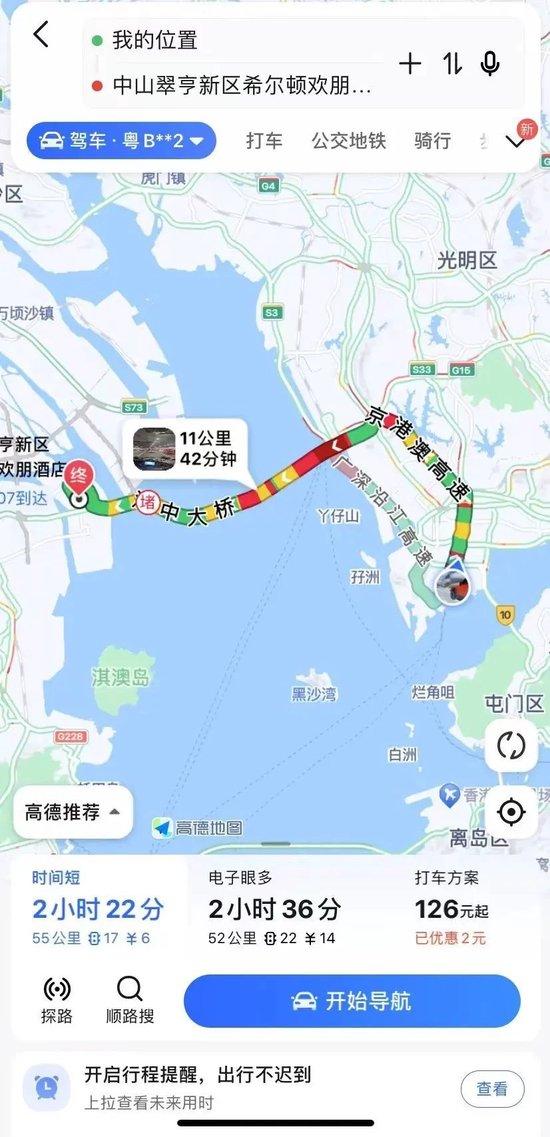
也有不少市民朋友提出
想自驾打卡
自驾指引路线如下
👇👇👇

计划打卡深中通道的朋友
注意这3件事
01
注意限速


02
禁止违停


03
警惕二次事故


同时,一系列路网交通设施也伴随深中通道同步建成。广深沿江高速二期工程“深中通道深圳侧接线”将增强深圳东西高速道路主骨架的联系,运力辐射珠江两岸。
深中跨市定制公交专线、深中跨市公交接驳线路、深中机场专线同步开通,位于中山博览中心的深中航空港将同步启用。大湾区内深圳、中山城市间“1小时”交通圈成为现实。
深中跨市公交
相关线路和价格表如下
👇👇👇

快来一起打卡
深中通道吧
来源 | 读特客户端
(责任编辑:时尚)
 即将影响上海!一航班遇上“台风眼”,旅客吓到惊声尖叫!最新路径→
即将影响上海!一航班遇上“台风眼”,旅客吓到惊声尖叫!最新路径→ 上海国际电影节|评委作品:大护法、涉过愤怒的海
上海国际电影节|评委作品:大护法、涉过愤怒的海 美媒:美国一架F
美媒:美国一架F TTS新传高级名词解释:视觉社交|视频正在成为新的纽带
TTS新传高级名词解释:视觉社交|视频正在成为新的纽带 2024年诺贝尔经济学奖揭晓
2024年诺贝尔经济学奖揭晓-
广州白云机场国际航线再+1 “贝尔格莱德—广州”航线成功首航
 9月30日晚,一架航班号为JU988的塞尔维亚航空航班飞抵广州白云国际机场,这标志着塞尔维亚航空“贝尔格莱德—广州”航线成功首飞,广州白云国际机场以民航界最高礼仪“水门礼”欢迎新航班的到来。该直飞航线
...[详细]
9月30日晚,一架航班号为JU988的塞尔维亚航空航班飞抵广州白云国际机场,这标志着塞尔维亚航空“贝尔格莱德—广州”航线成功首飞,广州白云国际机场以民航界最高礼仪“水门礼”欢迎新航班的到来。该直飞航线
...[详细]
-
 ▲ 点击上方 “晓敏青春说 ” → 点击右角“...” → 点选“设为星标 ★ ”“失去课间10分钟的中小学生,开始令人窒息的「厕所社交」。”“不能让一代人的童年回忆留在厕所。”如果不是全国政协委员
...[详细]
▲ 点击上方 “晓敏青春说 ” → 点击右角“...” → 点选“设为星标 ★ ”“失去课间10分钟的中小学生,开始令人窒息的「厕所社交」。”“不能让一代人的童年回忆留在厕所。”如果不是全国政协委员
...[详细]
-
TTS新传论文带读:戏里“王妈”戏外霸总!给打工人看生气了!!
 @TuTouSuo™️*小红书账号:秃头研究所新传考研/秃头研究所Monsters*如果你觉得自己读论文太过于盲目,不知道从哪里开始;如果你也想要通过碎片化的时间来补充和拓展知识储备;如果你想要一份直
...[详细]
@TuTouSuo™️*小红书账号:秃头研究所新传考研/秃头研究所Monsters*如果你觉得自己读论文太过于盲目,不知道从哪里开始;如果你也想要通过碎片化的时间来补充和拓展知识储备;如果你想要一份直
...[详细]
-
 记者丨尹可然就在上周末,天府新区已经率先完成了民办学校专项招生的报名。6月3日起,成都其他区市)县的民办学校也将开始报名。对家长们来说,最近这几天,就是考察学校的最后期限了。据我们统计,截至目前,共有
...[详细]
记者丨尹可然就在上周末,天府新区已经率先完成了民办学校专项招生的报名。6月3日起,成都其他区市)县的民办学校也将开始报名。对家长们来说,最近这几天,就是考察学校的最后期限了。据我们统计,截至目前,共有
...[详细]
-
 继2025年春夏纽约、伦敦、米兰时装周的举办,巴黎时装周也在法国时间)9月23日压轴登场,10月1日收官落幕。巴黎,作为孕育Herems、CHANEL、VALENTINO的沃土,加上城市的韵味加持,巴
...[详细]
继2025年春夏纽约、伦敦、米兰时装周的举办,巴黎时装周也在法国时间)9月23日压轴登场,10月1日收官落幕。巴黎,作为孕育Herems、CHANEL、VALENTINO的沃土,加上城市的韵味加持,巴
...[详细]
-
 北京时间5月27日晚,2024年法网公开赛上演一场焦点之战。在男单首轮比赛中,法网14冠王纳达尔对阵赛会4号种子兹维列夫,最终纳达尔以3比6、6比7、3比6的比分三盘落败。纳达尔近两年纳达尔深受伤病困
...[详细]
北京时间5月27日晚,2024年法网公开赛上演一场焦点之战。在男单首轮比赛中,法网14冠王纳达尔对阵赛会4号种子兹维列夫,最终纳达尔以3比6、6比7、3比6的比分三盘落败。纳达尔近两年纳达尔深受伤病困
...[详细]
-
 5月24日,上海音乐学院声乐歌剧系副教授宗师在德国维尔德堡“罗西尼音乐节”上演出的《阿尔米达》,由拿索斯唱片欧洲部)进行全球发行。唱片封面《阿尔米达》是意大利歌剧巨匠罗西尼的一部庄严歌剧,1817年1
...[详细]
5月24日,上海音乐学院声乐歌剧系副教授宗师在德国维尔德堡“罗西尼音乐节”上演出的《阿尔米达》,由拿索斯唱片欧洲部)进行全球发行。唱片封面《阿尔米达》是意大利歌剧巨匠罗西尼的一部庄严歌剧,1817年1
...[详细]
-
 5月28日晚,在厦门的网红圣地椰风寨沙滩,一汽奔腾旗下首款微型电动车“小马”上市。新车一共提供两种续航版本,122km和170km,售价在2.69万-3.19万元。再次看到一款微型车上市,我的第一反应
...[详细]
5月28日晚,在厦门的网红圣地椰风寨沙滩,一汽奔腾旗下首款微型电动车“小马”上市。新车一共提供两种续航版本,122km和170km,售价在2.69万-3.19万元。再次看到一款微型车上市,我的第一反应
...[详细]
-
继2025年春夏纽约、伦敦、米兰时装周的举办,巴黎时装周也在法国时间)9月23日压轴登场,10月1日收官落幕。巴黎,作为孕育Herems、CHANEL、VALENTINO的沃土,加上城市的韵味加持,巴
...[详细]
-
 纳达尔。本文图片 CFP在法网首轮被兹维列夫直落三盘击败后,法网14冠王纳达尔将目光转向了7月的巴黎奥运会。赛后他透露,自己的下一个目标将是7月的巴黎奥运会,而不是草地大满贯赛事温网。今年6月3日,纳
...[详细]
纳达尔。本文图片 CFP在法网首轮被兹维列夫直落三盘击败后,法网14冠王纳达尔将目光转向了7月的巴黎奥运会。赛后他透露,自己的下一个目标将是7月的巴黎奥运会,而不是草地大满贯赛事温网。今年6月3日,纳
...[详细]

